
Problem description
We are building a food delivery application similar to Uber Eats or Deliveroo. The user can browse restaurants in their area, view the corresponding menus, and make one or more orders to their preferred address. The restaurant owners can view their orders sorted by timestamp and in real-time. The status of a delivery is tracked throughout its various stages: Pending, In Preparation, Prepared, Being Delivered and Delivered. The user can see the deliverer's position in real-time. Once the order is completed, the deliverer can mark it as "Delivered".
Back of the envelope estimates
- Total number of deliveries per second = 200,000
- Number of restaurants = 1,000,000
- Amount of storage per restaurant (photos + videos + metadata) = 500 Mb
- Total storage for all restaurants = 500 x 1,000,000 = 500,000,000 Mb = 500 Tb
- Number of daily active users = 10,000,000
- Total number of users = 100,000,000
- Storage per user (personal information + payment account + location) = 2 Mb
- Total storage for all the users = 200 Tb
Functional requirements
- Users can submit orders to restaurants
- Users can view the order status, if the order is on the way then the user should be able to track the deliverer and see the estimated time of delivery in real-time.
- Users can view a restaurant delivery's ETD (estimated time of delivery)
- Restaurant managers can view their orders queue
- Deliverers can mark their deliveries as "delivered"
- System admins can see the total purchases and delivery costs for a particular restaurants for a given period (ex. per month).
Out of scope:
- User payments
- Calculate ETD
High-level design
Below is a system diagram highlighting the components and actors in the system and how they are interconnected.
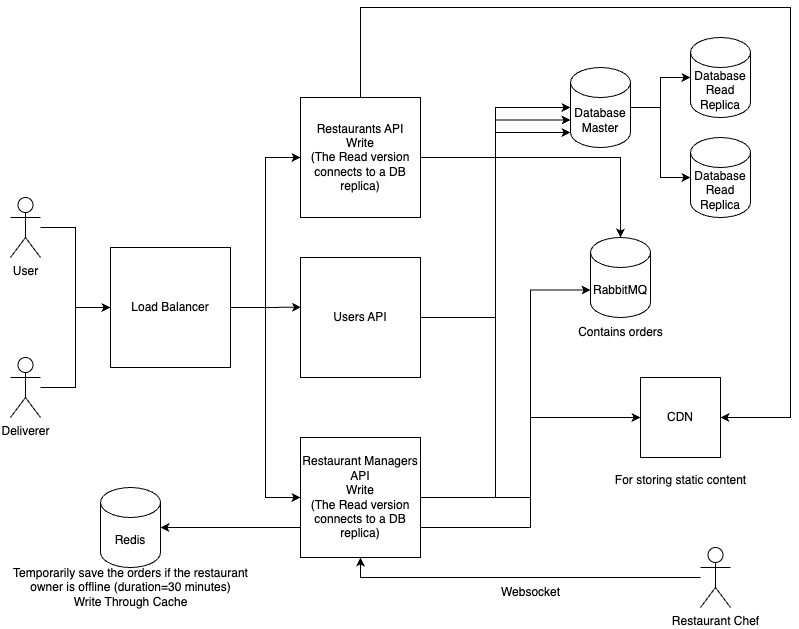
Restaurants API
- GET
/restaurants - GET
/restaurants/{restaurantId}/menus - POST
/restaurants/{restaurantId}/orders: submits an order - GET
/restaurants/{restaurantId}/orders/{orderId}
Users API
- POST
/authenticate - PUT
/users: sends the user's current location
Restaurant managers API
- GET
/clients/{clientId}/restaurants/{restaurantId}/orders - PUT
/clients/{clientId}/restaurants/{restaurantId}/orders: submits an order status including the deliverer's current location if the order is on the way.
Key characteristics of the system
- It is read-heavy (users browse restaurant menus more often than submitting orders)
- Relational data model
- Orders are sent in real-time thanks to the use of Redis caching, an in-memory message broker and web-socket connections
- Highly-available and fault-tolerant
Deep dive
Data model
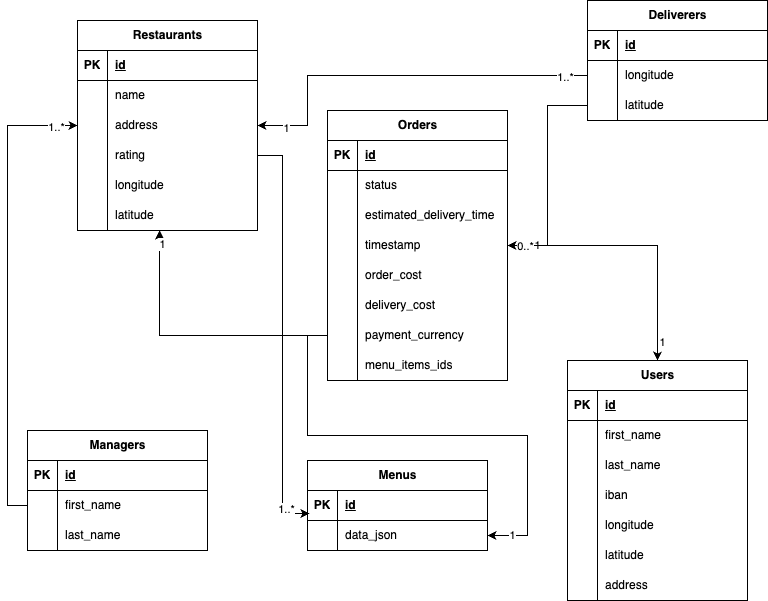
As mentioned, the system is read-heavy and the data model is relational therefore it makes sense to use a SQL database, our preferred choice is PostgreSQL since it is open source, widely supported and has exhaustive documentations online.
The users table is sharded by ID. The restaurants, orders and deliveries tables are sharded by geographical area (ex. a city). Another detail to note is that there will be frequent calls to update the deliverer's position and the order's ETD field.
Scalability
The number of deliveries per second 200,000, now assuming an average ETD of 10 minutes and a rate of 2 requests/second to update the deliverer's position and notify the user, then the total number of requests would be: 200,000 x (10 x 60 x 2) = 200,000 x 1200 = 240,000,000 requests/second.
Average data transfer per request = 16 bytes (2 x longitude and 2 x latitude) x 240,000,000 = 3.84 Gb/s.
This is a not a big number, a few high-end servers with high-speed internet connectivity can handle such a load. However since our system is elastic then we can distribute the load onto many server instances.
Assuming each instance can handle a data load up to 200 Mb/s then the total number of instances needed is: 3.84 x 1000 / 200 = 20.
For storage, we can a content delivery network which supports edge locations to deliver content (mainly restaurant media files) to users with the lowest latency.
RabbiMQ topic partitioning
The orders topic is partitioned by city ID. Partitioning by restaurant would require too many workers which is not ideal in terms of costs since most of the restaurants do not receive orders during closing time, and the number of orders per second doesn't justify the operational cost of running a dedicated worker.
Redis caching
The list of orders is partitioned by restaurant ID. The items in the list have a default time-to-live of 30 minutes. When the user cancels their order, the latter will be immediately removed from the cache.
Other considerations
Connection to the restaurant clients is maintained via web-socket. This ensures that the orders are sent in real-time.
Searching for restaurants within a specific area is a performance-critical operation that directly impacts the sales number. If the map is slow to load then users will most likely not bother to submit an order. To solve this issue, we can rely on geospatial queries. PostgreSQL has a module called PostGIS that provides this feature. For creating a restaurant index based on the longitude and latitude coordinates, we can use the S2 library.
Conclusion
We have a proposed a possible solution to the problem of designing a food delivery system similar to Uber Eats. Of course this design is not complete but it might serve as a base for someone who wants to study how large scale systems work. In a real project, it is extremely important to benchmark the performance of the chosen systems before committing to them and test their behaviours when pushed to their limits both in terms of handling large data volumes or a high number of requests.
Thanks for reading