
Why a database
The choice of the right database is crucial in any application that requires:
- Persisting large amounts of data
- Querying data based on complex criterion
- Accurate representation of persisted data: strong vs eventual data consistency
Databases architecture usually mirrors the kind of data they store and generally they are designed after the type of data they aim to efficiently process. For relational data, the obvious choice is SQL-based databases (Oracle, Microsoft SQL, Postgresql...). For document-based, it is MongoDB, for timeseries data, it is InfluxDB, for graph data, it is GraphDB...
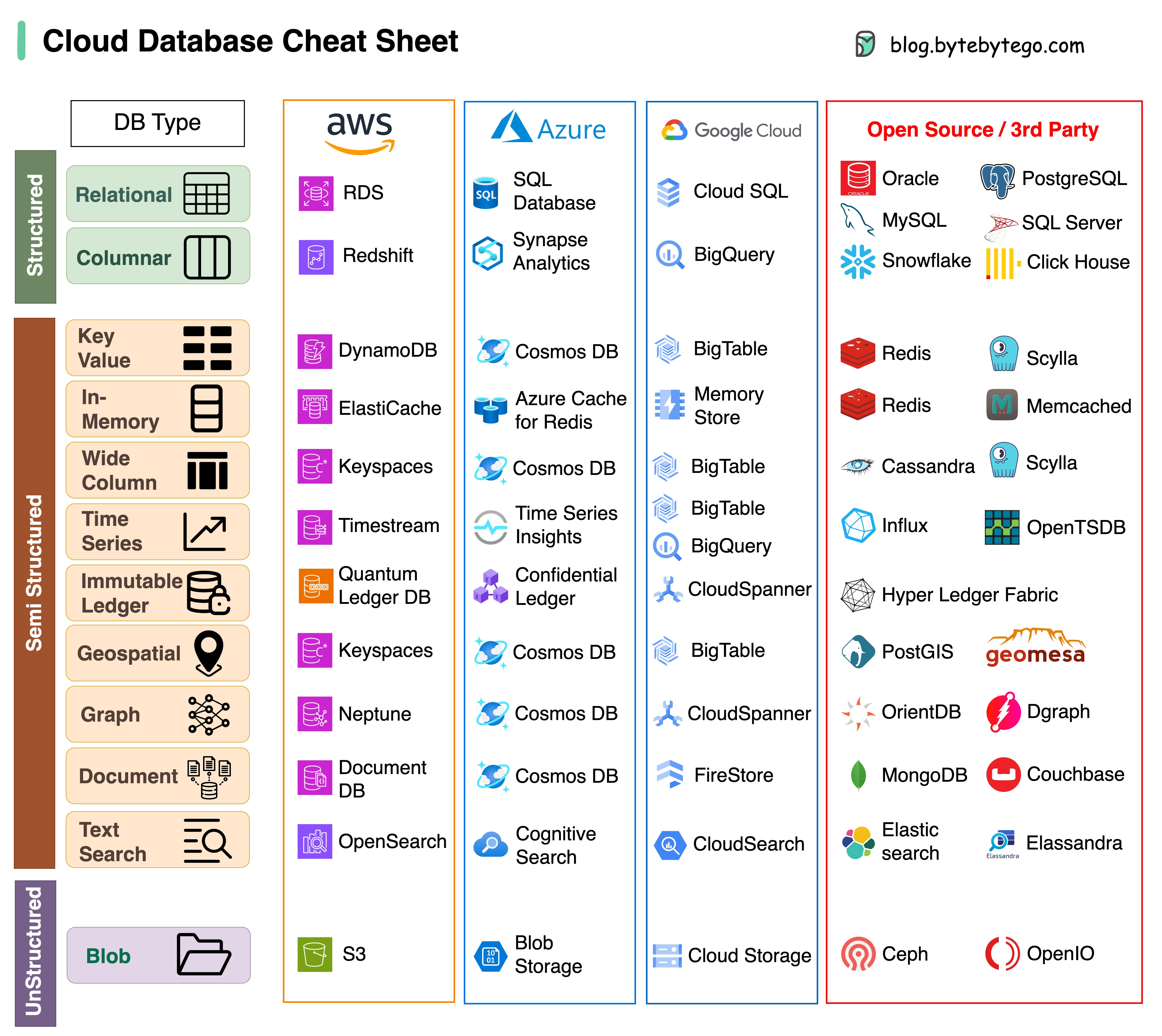
Some databases also support a column-based structure where data is grouped into an arbitrary number of columns. This enables efficient querying of a subset of data based on a set of columns, which in turn saves network bandwidth and reduces the data transfer time over the wire. CassandraDB and HBase are two popular columnar databases.
Of course we cannot discuss databases without talking about ACID properties. ACID (Atomicity, Consistency, Isolation, Durability) is a property of SQL-based databases. It guarantees that writing operations on the database will leave the data in a consistent state even during concurrent writes. In other words, all writing operations, even if run in parallel, will be executed as if they were run sequentially. This results in improved data integrity because data can no longer be corrupted during persistence which greatly improves the reliability of the database and makes it a great choice for data-sensitive applications like banking applications where even the slightest risk of having corrupted data is non-negotiable. However there is a cost to pay for having higher consistency and reliability. But before we delve into that, let's first talk about the CAP theorem.
CAP Theorem
The CAP theorem stands for Consistency, Availability and Partition Tolerance. It is a theoretical construct based on empirical data which says that for any distributed system only two out of three properties can be guaranteed:
- Consistency and availability
- Consistency and partition tolerance
- Availability and partition tolerance
Consistency means that at any point in time, the system always returns the most up-to-date data. This is very desirable in financial applications where errors due to the wrong manipulation of data is hard or even impossible to fix without serious financial loss.
Availability simply means that the system is always available. This is achieved by creating replicas which will take over when one or more components goes offline.
Finally, partition tolerance is the ability of the system to handle network failures or outages. For instance when a microservice goes down, can the system still function and process the requests (or a subset thereof) even when not all of its capabilities are functioning?
Back to the numbered points above, let us discuss the pros and cons of each type.
For CA, the main issue is slow data replication. Any time a write-request is executed, it has to be propagated to all the replicas (this depends of course on the replication topology). However as the data grows in size, the aforementioned process becomes too slow and unfeasible. In that case, the data has to be partitioned and sharded using a careful sharding strategy (geographical, range-based, user-name...) depending on the application use cases.
CP systems continue to work even when one or more requests were dropped. For example due to service outages, or connection issues, however the system may not be able to process all incoming requests successfully, which means that its availability will decrease.
Finally for AP, the system is capable of processing all requests and returning a non-error response. The system also functions in case of partial failures, however the returned data may not always be up to date.
In summary to choose a database, we can make our decision based on a discussion revolving around these points below:
- Type of data: on one extreme we have structured data (ex. relational) and on the other end, unstructured data (ex. images, videos...)
- Access pattern: whether the application is write-heavy or read-heavy
- Consistency: Strong or eventual consistency
Conclusion
Choosing the right database is an important decision that greatly impacts the application performance as the application scales to serve more users and store bigger amounts of data. Before finalizing the decision, a database must be carefully tested against current and hypothetical future use cases to see how it behaves when pushed to its limits. Like many things in software engineering, there is no one-fits-all solution, we need to consider our application data needs carefully and select the database that is optimized for such needs.